1. GIN 인덱스란?
Generalized Inverted Index의 약자이다. 이전 포스트인 full text search에서 사용하는 인덱스의 유형. 기본 구조는 B-tree와 유사하지만, 저장 형태가 다르다. 저장된 요소 자제에 대한 검색이 아닌 인덱스 컬럼의 값을 split 한 token인 lexeme 배열에 대해서 검색을 한다. array_ops, tsvector_ops, jsonb_ops, jsonb_path_ops 등 의 built-in operators를 통해 접근이 가능하다.
2. full text search에서의 적용
2-1. 샘플 테이블 및 데이터 생성
create table ts(doc text, doc_tsv tsvector);
insert into ts(doc) values
('Can a sheet slitter slit sheets?'),
('How many sheets could a sheet slitter slit?'),
('I slit a sheet, a sheet I slit.'),
('Upon a slitted sheet I sit.'),
('Whoever slit the sheets is a good sheet slitter.'),
('I am a sheet slitter.'),
('I slit sheets.'),
('I am the sleekest sheet slitter that ever slit sheets.'),
('She slits the sheet she sits on.');
update ts set doc_tsv = to_tsvector(doc);
create index on ts using gin(doc_tsv);
select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
2-2. 조회 결과 및 플랜 확인
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
(4 rows)
doc
---------------------------------------------
How many sheets could a sheet slitter slit?
(1 row)
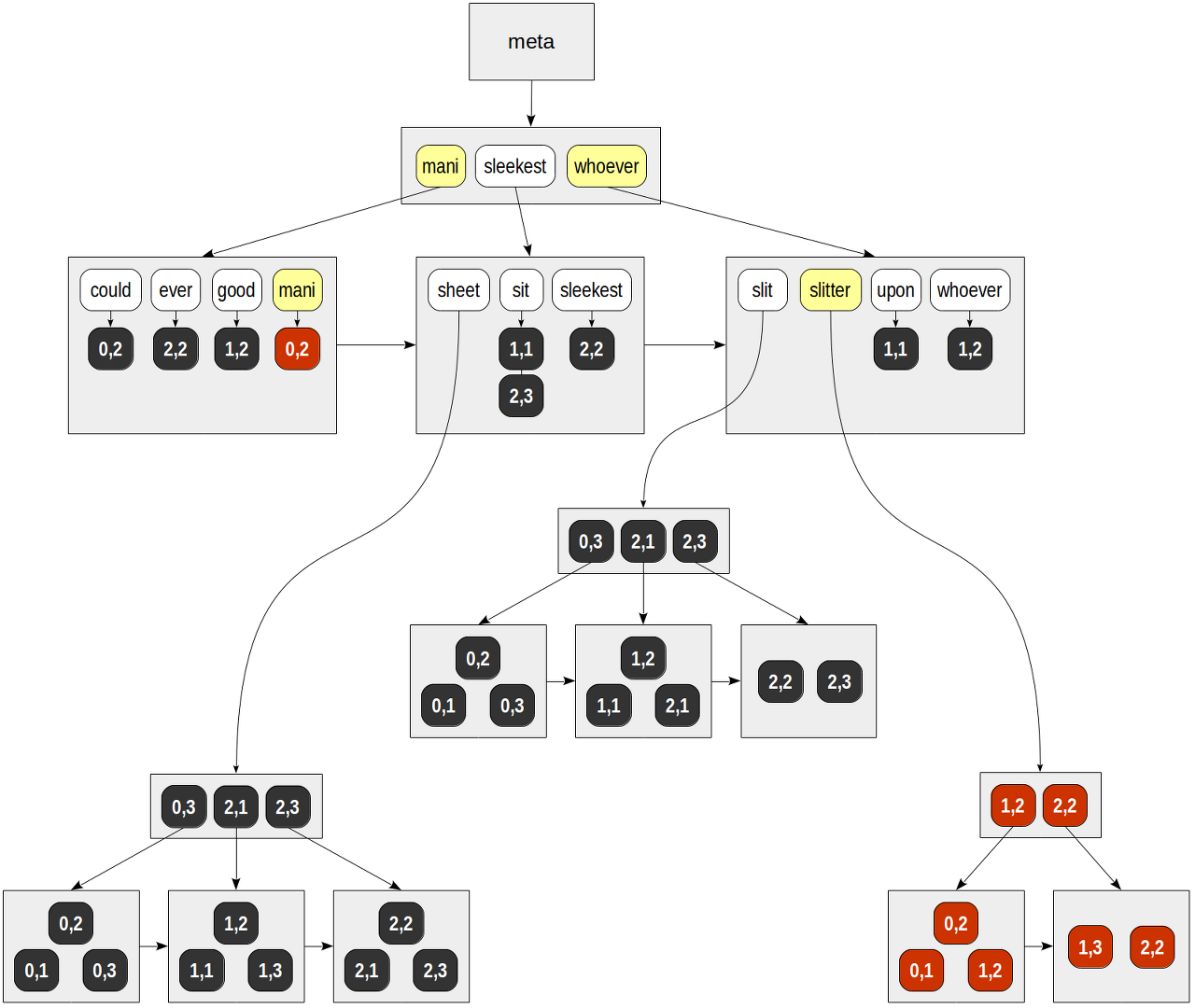
2-3. 작동 방식
▪ 먼저 쿼리에서 검색에 사용할 lexeme인 'many'와 'slitter'를 추출한다.
▪ lexeme B-tree에서 2개의 키를 동시에 찾는다.
- mani = (0,2)\
- slitter = (0,1),(0,2),(1,2),(1,3),(2,2) ▪ 마지막으로, 발견된 TID각각에 대해 검색 쿼리에 부합하는지 확인한다. (예제의 쿼리의 경우 and 조건이기에 (0,2)에 해당하는 TID만 리턴하게 된다.)
3. 특징
▪ GIN의 업데이트는 매우 느리다. document는 보통 많은 lexeme을 포함하고, 1개의 document가 업데이트되거나 추가된다고 해도 인덱스 트리 내에서는 많은 업데이트가 진행된다.
▪ 반면에, 몇몇의 document가 동시에 업데이트된다면, 중복되는 Lexeme들이 존재할 것이고, 총 인덱스 업데이트량은 개별 업데이트 시보다 줄어들 것이다.
▪ GIN인덱스의 또 하나의 특징은 항상 결과를 bitmap으로 리턴한다는 것이다. (TID 자체로 리턴하지 않는다.) 그렇기 때문에 Limit을 통한 결괏값 제한은 그렇게 효율적이지 않다.
▪ full text search, array, json 등의 타입 조회에 효율적이다.
참고 :