1. 중복 공백 제거
특정 문자열에 대해서 중복 공백 제거를 하고 싶다면 postgresql 정규식을 사용해서 가능하다.
(공백 외에 단일 문자에 대한 중복제거도 동일한 방법으로 가능하다.)
select regexp_replace(name, ' +', ' ', 'g') from TABLE; -- 'g' 옵션을 제거할 경우 최초 건에 대에서만 변경
2. 중복 단어 제거
컬럼 단위 중복제거는 distinct, group by를 통해 쉽게 가능하지만, 컬럼 내 문자열의 중복 단어 제거의 경우 다음과 같다.
(쉼표 기준으로 컬럼을 분리, 중복을 제거한 후 다시 연결)
select id, array_to_string(array_agg(distinct token), ' ') from (
SELECT unnest(string_to_array(COLUMN, ' ')) as token, id FROM TABLE) as tmp
group by id
3. 실습
3-1. 테이블 생성
-- 테스트 테이블 생성
create table duplicate_test (
id serial primary key,
name varchar(255) not null
);
3-2. 테스트 데이터 insert
-- 테스트 데이터 입력
insert into duplicate_test
(name)
values
('서울 서울 대구 서울 부산'),
('서울 서울 대구 서울'),
('부산 대구 대구 서울 서울서울 서울 광주'),
('서울 에서 대구 갔다가 부산 거쳐 다시 서울 로'),
('광주광주대구 대구 대 구 서울 '),
('서울 서울 서울 '),
('서울 대구 대 구 서울 '),
('서울 대구 대구 대 구 서울 '),
('서울 대구 대구 대구 부산부산 서울 부산 서울부 산')
;
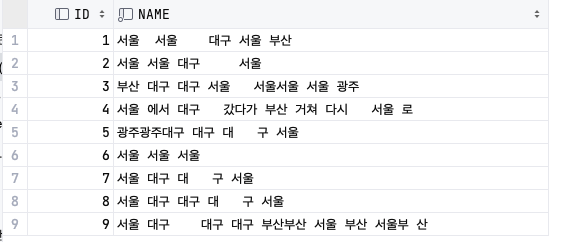
3-3. 중복 공백 제거
select regexp_replace(name, ' +', ' ', 'g') from DUPLICATE_TEST; -- 'g' 옵션을 제거할 경우 최초 건에 대에서만 변경
select regexp_replace(name, '단일문자열+', ' ', 'g') from DUPLICATE_TEST; -- 단일문자열에 대한 중복 제거도 동일한 방법으로 가능하다.

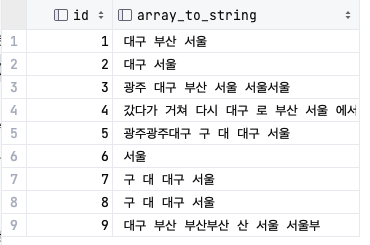
3-4. 중복 단어 제거
select id, array_to_string(array_agg(distinct token), ' ') from (
SELECT unnest(string_to_array(name, ' ')) as token, id FROM DUPLICATE_TEST) as tmp
group by id