몇 년 전 운영 프로젝트 설정 시 자세하게 봤던 내용이지만, 트래픽이 대폭 증가하고, DBMS에 연결된 프로젝트와 모듈이 늘어남에 따라 재설정을 위해 개념을 다시 정리하게 되었다.
1. 기본적인 데이터베이스 연결과정
- DB Connection 열기- 데이터베이스 드라이버를 사용하여 데이터베이스 서버와의 연결
- TCP 소켓 열기 - 데이터베이스 전송을 위해 TCP 소켓을 생성하고 데이터베이스 서버와 통신채널을 설정
- 데이터 통신 수행 - 생성된 소켓을 통해 SQL 쿼리를 전송하고 데이터를 Read / Write
- DB연결 닫기 - 데이터 통신이 완료되면 데이터베이스와의 연결을 종료
- TCP 소켓 닫기 - 사용한 TCP 소켓을 닫아 통신 채널 해제
웹 어플리케이션은 클라이언트의 HTTP 요청이 들어오면 스레드를 생성한다. 각 요청 시 DB서버로부터 데이터를 얻기 위해서 DB에 지속적으로 접근하는 작업이 필요하다. 스프링부트를 예로 들면, DB에 직접 연결하는 경우, JDBC 드라이버는 애플리케이션 시작 시 한번 로드되고, 사용자 요청 시마다 새로운 connection 객체 생성하여 데이터베이스에 연결한 후 종료되어야 한다. 이렇게 사용자 요청 시 매번 connection 객체를 생성/연결/종료해야 한다면 굉장히 비효율적이다.
2. Connection Pool
2-1. Connection Pool이란?
일정량의 컨넥션 객체를 미리 생성하여 pool에 저장하고, 클라이언트에서 요청이 오면 connection 객체를 빌려주고, 임무가 완료되면 다시 객체를 반납 받아서 pool에 다시 저장하는 기법이다. 일반적인 pool 패턴에서 사용되는 방식으로, 자원을 효율적으로 재사용함으로써 성능 최적화할 수 있는 방법이다.
스프링부트에선 컨테이너 구동시 일정 양의 connection 객체를 생성하여, 클라이언트 요청에 따라 데이터베이스 접근이 필요하면, connection pool에서 connection객체를 받아와 작업 후, 컨넥션풀에 다시 객체를 반납한다.
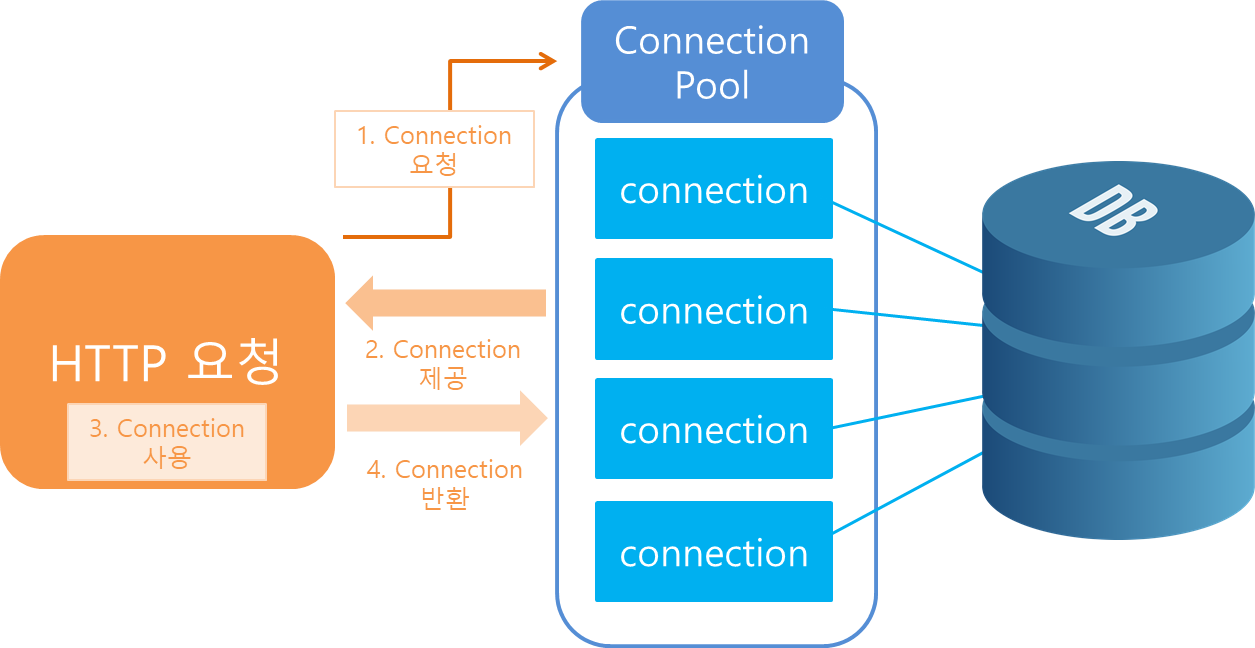
출처 : https://steady-coding.tistory.com/564
2-2. HikariCP Connection Pool 획득 과정
- 컨넥션 요청
- 이전에 사용했던 컨넥션 정보확인
- 이전에 사용했던 정보 중 컨넥션 가능한 존재 여부 확인
- 전체 컨넥션 목록 중 사용가능한 컨넥션 존재여부 확인
hikariCP에선 Thread가 연결요청시 컨넥션풀에 이전에 사용했던 컨넥션을 확인하고(3) 이를 우선반환하는 특징이 있다. 사용가능한 컨넥션이 없을 경우(4) HandOffQueue를 폴링 하면서 다른 Thread가 컨넥션을 반납하는 것을 기다린다. 지정 타임아웃 시간까지 대기하다가 시간이 만료되면 예외를 던진다.
객체를 획득해서 사용완료하면, 해당 객체를 컨넥션 풀에 반납한다. 컨넥션 풀은 사용내용을 관리하고, HandOffQueue에 반납된 컨넥션을 객체를 삽입한다. 해당 큐를 폴링하던 스레드는 컨넥션을 획득하고 작업을 처리한다.
3. Connection Pool 장점
- 불필요한 객체 생성/삭제가 사라지고, 클라이언트가 빠르게 데이터베이스에 접근 가능
- 디비 접속 모듈 공통화로 디비서버 환경이 바뀔경우 쉬운 유지보수
- 데이터베이스 컨넥션 수를 제한할 수 있어, 서버 자원을 효율적으로 관리 가능
- 연결이 끝난 컨넥션 객체를 재사용해서 객체 생성비용 감소
4. Connection Pool 설정시 주의사항
4-1. Connection Pool 증가
4-1-1. 과도한 데이터베이스 접속 발생 시 대기 문제
데이터베이스 접속이 너무 많이 발생할 경우, 컨넥션 수량이 한정되어있으면 반납할 때까지 계속 대기하게 된다. 그렇다고 컨넥션풀을 많이 생성하면, 커넥션이 메모리를 차지하고 서비스 성능을 떨어트린다.
-> 결국, 컨넥션 풀을 크게설정하면, 메모리 소모가 큰 대신 사용자 대기시간이 줄어들지만 컨넥션 풀이 작으면 그만큼 대기시간이 길어진다.
4-1-2. 컨넥션 풀 증가의 한계
이처럼 컨넥션풀이 늘어난다고 무조건 성능이 좋아지는건아니다. 컨넥션의 생성 주체는 결국 Thread이기 때문에 같이 고려해야 한다.
4-2. Connection Pool & Thread Pool
스레드 풀 - 데이터베이스 연결 요청을 처리하기 위해 풀을 설정하는 것처럼, 웹 애플리케이션은 클라이언트의 요청을 처리하기 위해 스레드를 할당받는다. 이 스레드가 데이터베이스 작업을 수행할 때 컨넥션 풀에서 객체를 빌려 사용하게 된다.
일반적으로 컨넥션 풀의 크기는 스레드 풀의 크기와 비슷하거나 약간 더 큰 정도로 설정한다.
4-3. Connection Pool, Thread Pool의 동시 증가
4-3-1. 메모리 소모 및 자원 비효율성
사용하지 않는 컨넥션들이 메모리만을 소비하게 되어, 메모리 사용량이 증가하고 시스템 자원이 비효율적으로 사용됨
4-3-2. 콘텍스트 스위칭 오버헤드
스레드 수가 증가함에 따라 운영체제가 스레드 간 콘텍스트 스위칭을 더 자주 하게 된다. CPU 리소스를 소모하게 됨으로 스레드 수가 과도하게 많아지면 전체 시스템 성능이 저하될 수 있다.
4-3-3. 데이터베이스 서버의 스레드 관리 부담
많은 수의 데이터베이스 연결은 데이터베이스 서버에서도 많은 스레드를 필요로 하고, 스레드 관리에 따른 오버헤드를 증가시킨다. 데이터 베이스 서버 측의 콘텍스트 스위칭 오버헤드도 증가하여 응답속도를 저하시킬 수 있다.
결국 스레드풀, 컨넥션풀을 계속 늘린다고 해서 성능이 계속 증가하는 것이 아니라 한계가 존재한다. 컨넥션 풀과 스레드 풀의 크기는 시스템의 하드웨어 사양, 애플리케이션의 특성, 데이터베이스 서버의 성능 등에 따라 최적의 크기가 다르다. 이 최적의 크기를 초과하여 풀을 늘리면, 오히려 성능이 저하될 수 있다.
5. 적정 Connection Pool
5-1. HikariCP 공식문서 적정 Connection Pool
히카리 CP 기준 공식 문서에 따르면 다음과 같이 적정 컨넥션 풀을 정의하고 있다.
1 connections = ((core_count) * 2) + effective_spindle_count)
- core_count - 현재 사용하는 서버 환경에서의 CPU 개수, CPU코어 수는 동시에 처리할 수 있는 스레드의 기본 수용능력을 나타냄
- core_count * 2 : 공식 문서에서는 스레드 풀의 스레드 수를 CPU코어 수의 2배로 설정하는 것을 권장, I/O 작업으로 인한 블로킹 시간 동안 다른 스레드가 CPU를 활용할 수 있게 하기 위함
- effective_spindle_count - 기본적으로 디비 서버가 관리할 수 있는 동시 I/O요청수
- 하드 디스크 하나는 spindle 하나를 갖는다 spindle은 디스크의 물리적 회전축을 의미
- 디스크가 16개인 경우, 시스템은 동시에 16개의 I/O처리 가능
- 이는 데이터베이스 서버가 효율적인 디스크 사용을 위해, 동시에 처리할 수 있는 I/O 작업의 수를 제한한다.
5-2. 서버 환경 예시
- CPU 코어 수 : 8개
- 디스크 스핀들 수 : 16개 (디스크 16개 기준)
- 적정 컨넥션 풀 크기 계산 :
(8 × 2)+16=32
따라서 이 서버의 적정 컨넥션 풀의 크기는 32이다.
6. HikariCP 옵션
- auto-commit (default: true) 커넥션 종료 또는 풀에 반환 시 트랜잭션을 자동으로 커밋할지 결정
- connection-timeout (default: 30000ms) 풀에서 커넥션을 얻기 위해 기다리는 최대 시간을 설정, 초과 시 SQLException 던짐
- idle-timeout (default: 600000 ms) 풀에 미사용 커넥션을 유지하는 시간을 지정, minimum-idle보다 작게 설정 시에만 적용
- max-lifetime (default: 1800000 ms) 풀에서 커넥션이 유지될 수 있는 최대 수명 시간을 설정, 사용 중이지 않을 때만 제거
- minimum-idle (default: maximum-pool-size) 풀에서 항상 유지할 최소 커넥션 수를 설정, 최적의 성능을 위해 maximum-pool-size와 동일하게 설정 권장
- maximum-pool-size (default: 10) 풀에서 유지할 수 있는 최대 커넥션 수를 설정, 데이터베이스 부하에 따라 조정
- pool-name (default: auto-generated) 풀의 이름을 지정하여 로깅이나 JMX 관리 콘솔에 표시
- initialization-fail-timeout (default: 1ms) 초기 커넥션 생성 실패 시 풀 초기화를 빠르게 실패하도록 설정
- validation-timeout (default: 5000ms) 커넥션 유효성 검사를 수행할 때 사용할 타임아웃 시간 지정
- connection-test-query (default: none) JDBC4 드라이버 미지원 시 유효한 커넥션인지 확인하기 위한 쿼리 설정
- read-only (default: false) 풀에서 커넥션을 획득할 때 읽기 전용 모드로 설정하여 최적화 지원
- transaction-isolation (default: none) java.sql.Connection에 지정할 트랜잭션 격리 수준 설정
- category (default: none) 커넥션에서 사용할 카테고리를 결정, 설정 없을 시 JDBC 드라이버 기본값 사용
- leak-detection-threshold (default: 0ms) 커넥션 누수 감지를 위해 커넥션 풀에 반환되기 전 허용할 최대 시간 설정
- Statement Cache 각 커넥션마다 PreparedStatement 캐싱, 데이터베이스 드라이버 설정을 통해 관리
- driver-class-name (default: none) 특정 드라이버를 명시적으로 설정 시 사용, 지정 시 jdbc-url 반드시 설정정
- registerMbeans (default: false) JMX 관리 Beans에 풀을 등록할지 여부 설정
참고