
1. RDS란?
RDS는 클라우드에서 데이터베이스를 쉽게 설정, 운영 및 확장할 수 있는 완전관리형 오픈소스 관계형 데이터베이스이다.
온디맨드, 혹은 예약형 인스턴스 구매로 유연한 데이터베이스 관리가 가능하며 스토리지 및 메모리 등의 설정에 따라 금액이 달라진다.
2. RDS 비용을 결정하는 요소
- DB 인스턴스 가용시간 - 1초 단위로 청구되며 1회 최소 10분 과금
- 스토리지 (월별 GB당) - DB인스턴스에 프로비저닝 한 스토리지 용량
- 월별 I/O - 총 스토리지 I/O 요청 수
- 백업 스토리지 - 자동 데이터베이스 백업 및 모든 데이터베이스 스냅샷과 연결된 스토리지
- 데이터 전송 - RDS에서 인스턴스를 통한 데이터 송수신
티어별 계산은 여기서 가능 (PostgreSQL 기준)
https://calculator.aws/#/addService/RDSPostgreSQLhttps://calculator.aws/#/addService/RDSPostgreSQL
초기 스타트업 및 신규 프로젝트의 경우 적정 스펙을 선택하는 것이 중요하며, 시스템 사양, 트래픽 (평균 유입량, 피크 지점의 유입량), IOPS 등 운영환경에 따라 비용이 급격하게 달라질 수 있다. 성능에 전혀 문제없는 스펙 차이인데도 10배 이상의 과금이 생기는 경우가 발생하기에 다양한 시뮬레이션을 통해 검증하고, 적용 후에도 모니터링을 통해 지속적인 튜닝이 필요하다.
3. RDS 주요 옵션
3-1. Deploy options
RDS의 비용을 결정하는 것 중 가장 큰 옵션 중 하나는 배포 옵션이다.
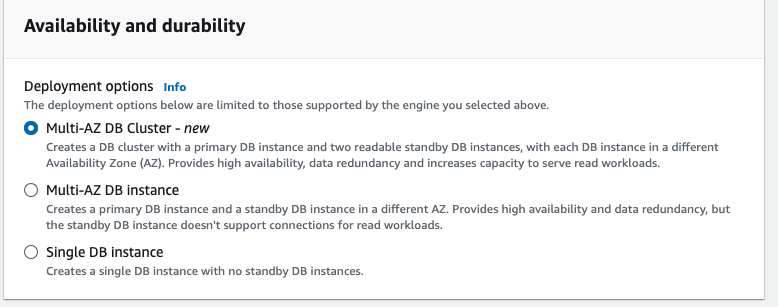
Multi-AZ DB Cluster
2개의 읽기 가능한 대기 인스턴스가 있는 다중 AZ배포로 메인 DB인스턴스를 생성한다. 서로 다른 AZ에서 동일 인스턴스를 프로비저닝 하고 유지관리 한다. 메인 DB 인스턴스에 영향을 미치는 계획이 생성되거나 중단되는 경우 대기 DB인스턴스 중 하나로 자동 장애복구를 수행한다.
Multi-AZ DB Instance
다른 AZ에 1개의 대기 DB인스턴스와 메인 DB 인스턴스를 동시에 생성한다. 1대의 대기 인스턴스가 장애 대응을 하지만, Multi-AZ DB Cluster 보다 read workload 처리를 덜하고, write 지연이 더 길다는 단점이 있다.
Single DB Instance
대기 인스턴스 없이 메인 DB인스턴스만을 생성한다.
설명 상으로는 Multi-AZ DB Cluster가 가장 좋지만, 그만큼 비용이 비싸다.
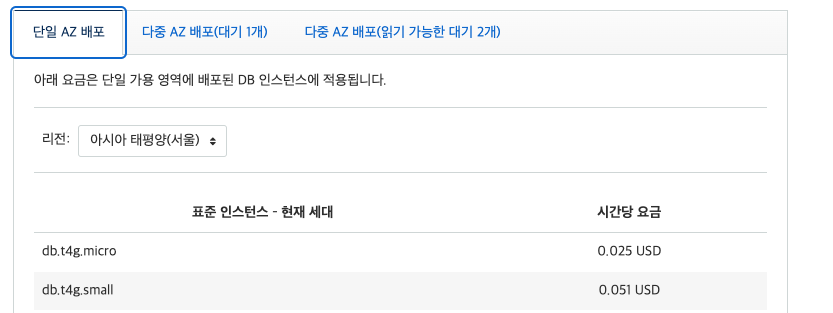
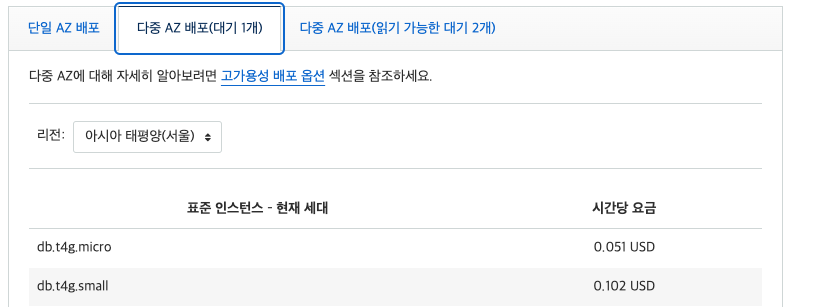
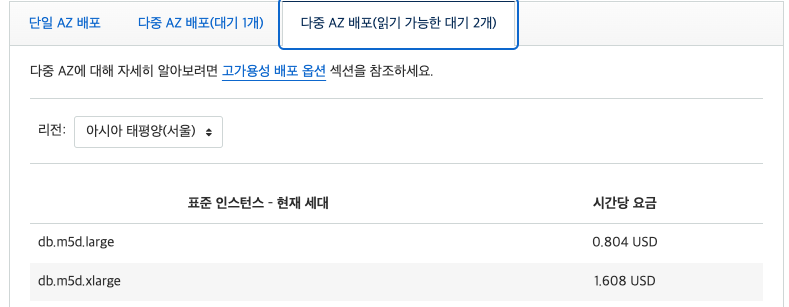
Single DB Instance에 비해 Multi-AZ DB Cluster는 약 30배가 넘는 과금을 부여하여 차이가 굉장히 크다. 실제 운영서버의 경우 실시간 장애대응 및 데이터백업이 필수이기에 최소 Multi-AZ DB Instance를 사용하여 무중단 운영 및 장애대응을 권장한다.
3-2. 인스턴스 유형
RDS Instance 티어는 크게 T, M, R로 나뉘며 용도 및 금액이 다르다.
T - 개발용, 특정 상황에 버스팅 되어 사용하는 시스템
M - 일반적인 운영 상황
R - 트래픽이 많고, 메모리 사용량이 많은 시스템
보통 일반 웹사이트, 시스템 운영에서는 M타입 내에서 사이즈, IOPS 선택 후 모니터링을 권장한다. 테스트 서버 혹은 사용자가 적은 단계에서는 T티어로 운영이 가능하지만, T티어 (T4g, T3 제외)의 인스턴스는 일정 크레딧을 보유한 채로 시작하여 인스턴스가 사용될 경우에 크레딧을 차감하는 방식으로 운영되며, 크레딧이 모두 소모될 경우 DB성능이 급격하게 저하되기 때문에 크레딧, CPU, 메모리 모니터링 및 Cloud watch로 크레딧 리밋을 설정하며 관제하는 것을 권장한다.
RDS->Databases->Monitoring에서 인스턴스 현재 밸런스 확인 가능
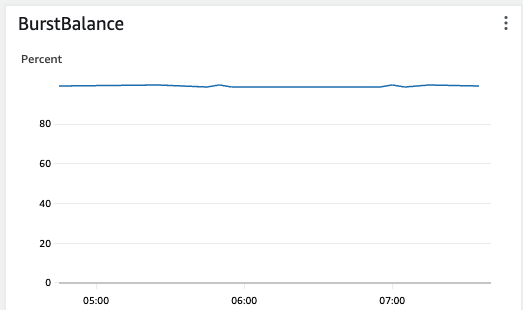
실제 크레딧이 0인 채로 10분 이상 지속된 경우 1초 이내 수행되던 쿼리가 8초 이상 지연 (연결 자체가 끊기진 않았다.)되며 시스템에 큰 문제를 일으킨 적이 있다.
4. RDS 인스턴스 선택
현재 DB의 잉여자원이 많지 않은지 지속적인 모니터링을 하는 것이 중요하다.
또한 단순히 DB 속도가 느려졌기에 인스턴스를 스케일 업 하는 것이 아닌, 정확한 원인파악 후 그에 맞는 튜닝을 하는 것이 중요하다. (스케일 업보다 쿼리 최적화, 주요 로직 개선으로 성능 문제를 해결할 수 있는 경우도 있다.)
예를 들어 m5.large 티어를 사용 중 스케일업을 고려하고 있다면 m5.xlarge 외에 r6i.large도 같이 고려 대상이 될 수 있다.




메모리 최적화 r모델의 경우, CPU는 유지한 채 메모리만 16 GiB로 증가시킨 인스턴스로, 현재 데이터베이스에서 메모리 증가의 니즈만 있다면 m5.xlarge (시간당 $0.494) 대신 r6i.large (시간당 $0.30)으로 비용 절감 효과를 볼 수 있다.
또한, 컨넥션 풀을 늘려야 하는 상황에서도, 무조건 다음 단계의 인스턴스를 사용하는 것보다는 필요한 자원만을 최적화하여 스케일업 하는 것이 좋다. Postgresql 기준으로 최대 동시 연결 숫자는
LEAST({DBInstanceClassMemory/9531392}, 5000)
로 기본 설정되어 있으며, 이는 인스턴스 메모리의 영향을 받는다. 그렇기에 메모리를 증가시키는 인스턴스 스케일업을 해야 컨넥션 풀이 늘어난다.
신규 인스턴스의 최적화 자원을 찾는 것만큼, 기존 인스턴스가 최적화되어 있는지 모니터링이 필수이다.
RDS->Databases의 Monitoring탭에서 상세 자원현황을 확인가능하다. (다음은 주요 지표들이 모니터링되는 현황이다. IOPS, Latency, Memory, CPU 등)
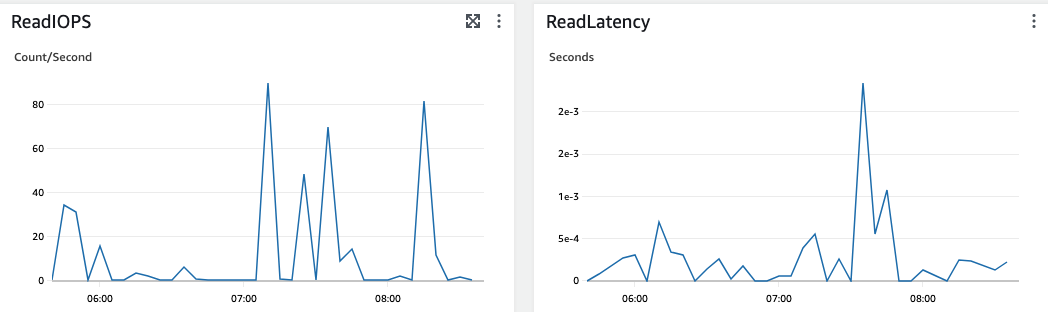
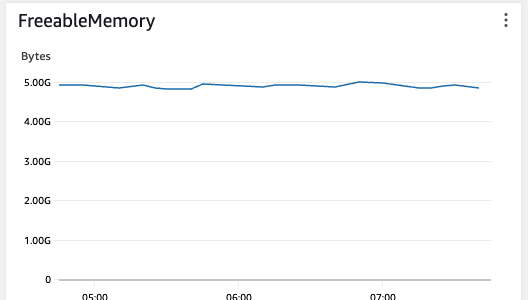
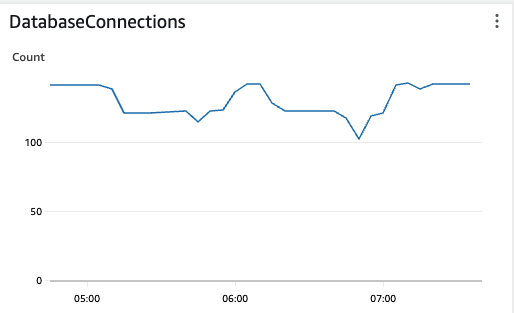
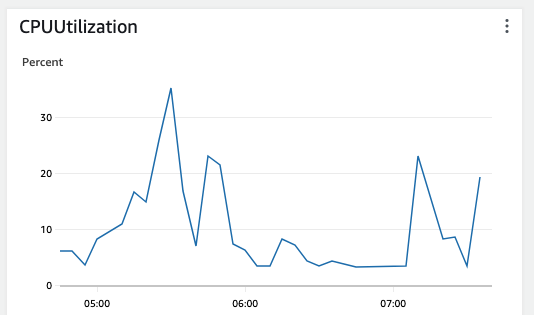
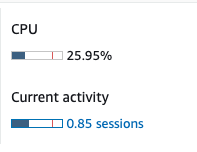
마지막 캡처의 CPU 같은 경우 70~80% 이상(25.95% 바의 빨간색 선)이 넘을 경우 붉은 그래프로 변하며 위험 수준을 알려준다. 현재 시스템이 사용자가 많고 불안정하다면 기본 수치보다 낮은 수치로 Cloud Watch와 연결하여 모니터링하는 것을 권장한다.
5. 비용 최적화
5-1. T티어 사용 시
T 티어를 사용 중인데 크레디트가 바닥을 치는 경우가 자주 있다면 AWS 공식 가격표에서 보이는 가격이 M티어가 더 싸더라도 동일 환경에서 시뮬레이션을 돌려보는 것이 좋다. T티어의 경우 24시간 평균 CPU 사용률이 인스턴스 기본 사용률을 초과하면 추가 요금이 과금되기 때문이다.
5-2. 인스턴스 유동적 운용
DB를 상시 운영할 필요가 없다면, RDS 인스턴스는 가용 중인 시간을 1초 단위로 (1회 최소 10분 요금) 청구되기에 인스턴스를 유동적으로 관리하는 것도 비용 측면에서 고려해 볼 만하다. (운영 DB인스턴스를 부분적으로 사용하는 것은 부담이 크니 테스트 및 개발 시스템에서만 적용하길 권장)
5-3. 예약형 인스턴스
운영 인프라가 안정화되고, 향후 예상 트래픽이 어느 정도 확정되고 나면, 온디멘드가 아닌 예약형 인스턴스로 변경해서 사용하면 비용 절감효과를 볼 수 있다. 일정 기간 동안 정해진 규격의 인스턴스를 예약해서 사용하는 기능으로 비용이 약 25~41% (1년 예약, Seoul Region 기준) 저렴하다. 다만 인스턴스 스케일업, 스케일 아웃은 가능하지만 스케일 다운은 불가능하기에 예상 사용량을 정확히 파악하여 사용하는 것을 권장한다. 1년 혹은 3년 선택가능하고 3년 선택 시 비용절감 폭이 50% 이상으로 대폭 증가하지만, 3년 동안 고정된 스펙의 인스턴스를 사용해도 문제 되지 않는 상황인지 정확한 파악이 필요하다.
5-4. Deploy Options
개발, 테스트 데이터 베이스이고 즉각적인 백업이 중요하지 않다면, Single DB Instance로 설정을 변경하면 Multi-AZ DB Instance 대비 절반, Multi-AZ DB cluster 대비 30배 이상의 비용절감 효과를 볼 수 있다. (운영에는 적어도 Multi-AZ DB Instance를 사용하는 것을 권장)
5-5. 모니터링
RDS 인스턴스는 트래픽, 데이터 양, 운영 중인 시스템 등의 상황에 맞춰 최적화된 인스턴스를 선택 후, 주요 자원들에 대한 모니터링을 통해 성능 및 비용 최적화를 지속적으로 하는 것이 중요하다.
참고