PostgreSQL에서 문자열을 다루는 다양한 방법이 있다. 그중 문자열을 원하는 방식대로 자를 수 있는 함수들에 대해 알아보자. 먼저, 가장 많이 쓰이는 SUBSTRING, SUBSTR의 기본 사용 법 및 응용, 성능에 대해 알아보자.
1. Substring 기본 사용법
Substring과 Substr은 시작 위치(n), 길이(l)를 기준으로 문자열을 자를 수 있다.
SELECT substring('문자열' FROM n FOR l); -- from, for 구문은 substring만 지원
SELECT substring('문자열', n, l);
SELECT substr('문자열', n, l);
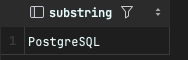
구문을 활용하여 PostgreSQL Tutorial 문자열에서 첫번째 위치인 P부터 10개의 문자열만을 추출하는 예제를 확인해 보면 동일한 결과를 확인할 수 있다.
SELECT substring('PostgreSQL Tutorial' FROM 1 FOR 10);
SELECT substring('PostgreSQL Tutorial', 1, 10);
SELECT substr('PostgreSQL Tutorial', 1, 10);
2. Substring 뒤에서
뒤에서부터 (오른쪽에서 부터) 문자열을 추출하려면, 문자열의 길이를 계산한 후, 시작 위치를 해당 길이에서 빼는 방식으로 적용이 가능하다.
예제 1 - 뒤에서 3개 문자열 추출
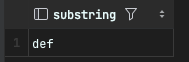
다음 예제는 특정 문자열 'abcdef'에서 뒤에 3개의 문자열 'def'를 추출하는 예제이다.
SELECT substring('abcdef' FROM char_length('abcdef') - 3 + 1); -- 3은 추출하고자하는 길이
 char_length('abcdef') - 3 + 1"는 “6 - 2 = 4"가 되며, 4번째부터 맨 끝까지 문자열을 추출하게 된다.
char_length('abcdef') - 3 + 1"는 “6 - 2 = 4"가 되며, 4번째부터 맨 끝까지 문자열을 추출하게 된다.
예제 2 - 뒤에서 4개 문자열 추출
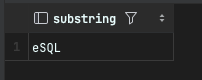
다음은 'PostgreSQL' 문자열에서 뒤에서 4번째 글자부터 맨 끝 문자를 추출하는 예제이다.
SELECT substring('PostgreSQL' FROM char_length('PostgreSQL') - 4 + 1);
3. Substring 정규식으로 추출
3-1. 기본 Substring 정규식 추출
FROM 뒤에 정규식을 추가함으로써 정규식 패턴매칭으로 문자열을 추출할 수도 있다.
SELECT substring('user@example.com' FROM '@(.+)$');
다음과 같이 적용하면 @뒤에 오는 모든 문자열을 추출하게 된다.
3-2. 그룹 Substring 정규식 추출
혹은 정규식에 매칭된 문자열이 여러 그룹이라면, 매칭되는 문자열그룹의 첫 번째 그룹만을 조회한다. 예를 들어 다음 정규식 문자열 자르기를 보면
SELECT substring('2024-07-24' FROM '([0-9]{4})-([0-9]{2})-([0-9]{2})');
{2024, 07, 24} 세 개의 그룹으로 정규식 매칭이 된다. 하지만 결과는 첫 번째 그룹인 2024만 조회된다. 즉, 다음 정규식 매칭 함수와 동일한 기능을 하게 된다.
SELECT (regexp_matches('2024-07-24', '([0-9]{4})-([0-9]{2})-([0-9]{2})'))[1];
4. Substring, Substr의 차이 (문법, 성능)
기본적으로 원하는 위치의 문자열을 자른다는 공통점이 있지만, SUBSTRING이 더 많은 기능을 제공한다, 특히 패턴 매칭이 가능하며, SUBSTR은 간단한 위치와 길이를 기반으로 문자를 추출할 때 사용한다.
성능 측면에서도 단순히 위치와 길이를 기반으로 문자열을 추출할 경우 동일하다, 둘 다 문자열 인덱싱을 통해 부분 문자열을 빠르게 추출한다. 다음은 두 함수의 성능을 비교하는 간단한 예제이다.
EXPLAIN ANALYZE
SELECT substring('abcdefghijklmnopqrstuvwxyz' FROM 2 FOR 10)
FROM generate_series(1, 1000000);

EXPLAIN ANALYZE
SELECT substr('abcdefghijklmnopqrstuvwxyz', 2, 10)
FROM generate_series(1, 1000000);

성능상 큰 차이가 없음을 확인할 수 있다.